原文转自:http://wiki.mbalib.com/wiki/%E7%BB%84%E8%B7%9D%E5%88%86%E7%BB%84
組距分組
組距分組(Interval Grouping)
什麼是組距分組
組距分組是將全部變數值依次劃分為若幹個區間,並將這一區間的變數值作為一組。組距分組是數值型數據分組的基本形式。
在組距分組中,各組之間的取值界限稱為組限,一個組的最小值稱為下限,最大值稱為上限;上限與下限的差值稱為組距;上限與下限值的平均數稱為組中值,它是一組變數值的代表值。
組距分組的步驟
例如,某生產車間50名工人日加工零件數如下(單位:個)。試對數據進行組距分組。
117
108
110
112
137 |
122
131
118
134
114 |
124
125
123
127
120 |
129
117
126
123
128 |
139
122
133
119
124 |
107
133
134
113
115 |
117
126
127
120
139 |
130
122
123
123
128 |
122
118
118
127
124 |
125
108
112
135
121 |
採用組距分組需要經過以下幾個步驟:
第一步:確定組數。一組數據分多少組合適呢?一般與數據本身的特點及數據的多少有關。由於分組的目的之一是為了觀察數據分佈的特征,因此組數的多少應適中。如組數太少,數據的分佈就會過於集中,組數太多,數據的分佈就會過於分散,這都不便於觀察數據分佈的特征和規律。組數的確定應以能夠顯示數據的分佈特征和規律為目的。在實際分組時,可以按Sturges提出的經驗公式來確定組數K:
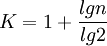
其中n為數據的個數,對結果用四捨五入的辦法取整數即為組數。例如,對前例的數據有: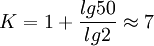 ,即應分為7組。當然,這隻是一個經驗公式,實際應用時,可根據數據的多少和特點及分析的要求,參考這一標準靈活確定組數。
,即應分為7組。當然,這隻是一個經驗公式,實際應用時,可根據數據的多少和特點及分析的要求,參考這一標準靈活確定組數。
第二步:確定各組的組距。組距是一個組的上限與下限的差,可根據全部數據的最大值和最小值及所分的組數來確定,即組距=(最大值-最小值)÷組數。例如,對於前例的數據,最大值為139,最小值為107,則組距=(139-107)÷7=4.6。為便於計算,組距宜取5或10的倍數,而且第一組的下限應低於最小變數值,最後一組的上限應高於最大變數值,因此組距可取5。
第三步:根據分組整理成頻數分佈表。比如對上面的數據進行分組,可得到下麵的頻數分佈表,見表:
某車間50名工作日加工零件數分組表
按零件數分組
頻數(人)
頻率(%)
105-110
110-115
115-120
120-125
125-130
130-135
135-140 |
3
5
8
14
10
6
4 |
6
10
16
28
20
12
8 |
| 合計 |
50 |
100 |
採用組距分組時,需要遵循“不重不漏”的原則。“不重”是指一項數據只能分在其中的某一組,不能在其他組中重覆出現;“不漏”是指組別能夠窮盡,即在所分的全部組別中每項數據都能分在其中的某一組,不能遺漏。
為解決“不重”的問題,統計分組時習慣上規定“上組限不在內”,即當相鄰兩組的上下限重疊時,恰好等於某一組上限的變數值不算在本組內,而計算在下一組內。例如,在表的分組中,120這一數值不計算在“115-120”這一組內,而計算在“120-125”組中,其餘類推。當然,對於離散變數,可以採用相鄰兩組組限間斷的辦法解決“不重”的問題。例如,可對上面的數據做如下的分組,如表:
某車間50名工人日加工零件數分組表
按零件數分組
頻數(人)
頻率(%)
105-109
110-114
115-119
120-124
125-129
130-134
135-139 |
3
5
8
14
10
6
4 |
6
10
16
28
20
12
8 |
| 合計 |
50 |
100 |
而對於連續變數,可以採取相鄰兩組組限重疊的方法,根據“上組限不在內”的規定解決不重的問題,也可以對一個組的上限值採用小數點的形式,小數點的位數根據所要求的精度具體確定。例如,對零件尺寸可以分組為10-11.99、12-13.99、14-15.99,等等。
在組距分組中,如果全部數據中的最大值和最小值與其他數據相差懸殊,為避免出現空白組(即沒有變數值的組)或個別極端值被漏掉,第一組和最後一組可以採取“××以下”及“××以上”這樣的開口組。開口組通常以相鄰組的組距作為其組距。例如,在上面的50個數據中,假定將最小值改為94,最大值改為160,採用上面的分組就會出現“空白組”,這時可採用“開口組”,如表:
某車間50名工人日加工零件數分組表
按零件數分組
頻數(人)
頻率(%)
110以下
110-115
115-120
120-125
125-130
130-135
135以上 |
3
5
8
14
10
6
4 |
6
10
16
28
20
12
8 |
| 合計 |
50 |
100 |
為了統計分析的需要,有時需要觀察某一數值以下或某一數值以上的頻數或頻率之和,還可以計算出累積頻數或累積頻率。
分享到:




相关推荐
对于组距分组数据,先找出出现次数最多的变量值所在组,即为众数所在组,再根据下面的公式计算计算众数的近似值。 下限公式: 式中: 表示众数;L表示众数的下线; 表示众数组次数与上一组次数之差; 表示众数组...
有关Java编写正态分布涉及到的函数!正态分组, 计算组距。
产品运营数据分析——SPSS数据分组案例.pdf
为减小传统串行干扰抵消(SIC)检测器的时延,改善每一级的检测性能,采用对角加载法和组距分组法,提出了一种改进的SIC检测器。该检测器对每一级用户特征波形的相关矩阵进行对角加载,通过加载量的选择,使得分组用户的...
这⾥的组距式分组,也会分为两种的,⼀个是等距分组,这种⽅法适⽤在连续数据分布相对均匀的;另⼀个 是不等距分组,适⽤在连续数据分布不均匀的状态。具体使⽤见下⽂: a.等距分组: 第⼀步:确定维度、组数; 第⼆步:...
用C语言实现相容信道组的信道配置,使用两种方法进行分配:分区分组配置法和等频距配置法,
因此,分组数据是已被组织成称为类的组的数据。 可以通过构建一个显示变量频率分布的表格(其值在原始数据集中给出)来组织原始数据集。 这种频率表通常称为分组数据。 在这里,我们开发了一个 m 代码来计算分组...
对差错编码原理进行叙述,分组码一般可用(n,k)表示。其中,k是每组二进制信息码元的数目,n是编码码组的码元总位数,又称为...简单地说,分组码是对每段k位长的信息组以一定的规则增加r个监督元, 组成长为n的码字。
第一章 前言 第二章 多源关联分片* 理解多源分片的概念与特征 体会多源分片报表的制作 理解扩展模型、主格模型 在报表中使用多个数据集,并在报表中使其数据相关 设计多源交叉报表 人为定义主格 ...全距图
5、组距,数据有误或数据均相同时返回0 6、获取组内左边界 7、获取组内右边界 8、获取组内中值 9、分布密度 10、获取正态分布数据密度 11、获取单个正态分布数据 12、获取组内正态分布数据密度 13、获取准确度 14、...
对定量数据的分布分析按照以下步骤执⾏: 1:求极差 2:决定组距与组数。 3:决定分点。 4:得到频率分布表。 5:绘制频率分布直⽅图 遵循的原则有: 1:所有分组必须将所有数据包含在内。 2:各组的组宽最好相等。...
已有的基于差分隐私的直方图发布技术在利用直方图反映数据的真实分布特征时可能会...并且为每组添加符合拉普拉斯(Laplace)机制的噪声时,根据组距为每组设置合理的隐私预算,在一定程度上提高了不同数据段的隐私性。
针对精密测角法标定测绘相机...实验数据显示,在相同试验环境条件下,分组渐进标定算法中主点、主距标定精度比精密测角算法分别提高了2.43倍和2.00倍,可达到2.12 μm和4.02 μm,表明分组渐进标定算法提高了标定精度。
构造了3种带参数的三角样条基,基于这3组基定义了3种三角样条曲线。与二次B样条曲线类似,这3种曲线的每一段都由相继的3个控制顶点生成,且这3种曲线具有许多与二次B样条曲线类似的性质。但这3种曲线的连续性都比二...
组数:极差 / 组距,也就是 (最大值-最小值)/ 组距 频数分布直方图与频率分布直方图,hist()方法需增加参数normed 注意:一般来说能够使用plt.hist()方法绘制的直方图是那些没有统计过的数据,如果是统计过的...
对营销数据进 行分组和统计分析,研究数据的集中趋势 和分布特征 一、业务分组:按定性数据(业务属性) 二、分组依据定量数据分组 1、箱线图分析 2、定量数据的等距和非等距分组 业务分组 品牌 网龄 ARPU 计数项 ...
根据频数分布表,在横轴上以每组对应的组距线段(xiànduàn)为底,以该组的频数为高,作出7个矩形所组成的直方图(histogram),参见下图。 第十九页,共36页。 第二十页,共36页。 直方图的观察(guānchá)与分析 ...
Allegro线宽、间距、等长、差分规则设置
小结 5.3关联规则主要介绍了Apriori算法,以在一个数据集中找出各项...聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度 将他们划分为若干组,划分的原则是组内样本最小化而组间(外部)距 离最大化
用最优化处理方法,按DBZ值大小分组统计,得到了这一地区Z-I关系的序列。然后,用这组关系得到降雨的雷达估算值。试验结果表明,距雷达50―100km之间的区域雷达定量测雨的精度较好。和雨量计测值比较,雷达估算的单...