java-mans
- 浏览: 11427281 次
-

最新评论
-
wahahachuang8:
我觉得这种东西自己开发太麻烦了,就别自己捣鼓了,找个第三方,方 ...
WebSocket和node.js -
xhpscdx:
写的这么详细,全面,对架构师的工作职责,个人能力都进行了梳理。 ...
架构师之路---王泽宾谈架构师的职责 -
xgbzsc:
是http://www.haoservice.com 吗?
android WIFI定位 -
lehehe:
http://www.haoservice.com/docs/ ...
android WIFI定位 -
lehehe:
http://www.haoservice.com/docs/ ...
android WIFI定位
Nonclustered Indexes页级别包含什么数据?
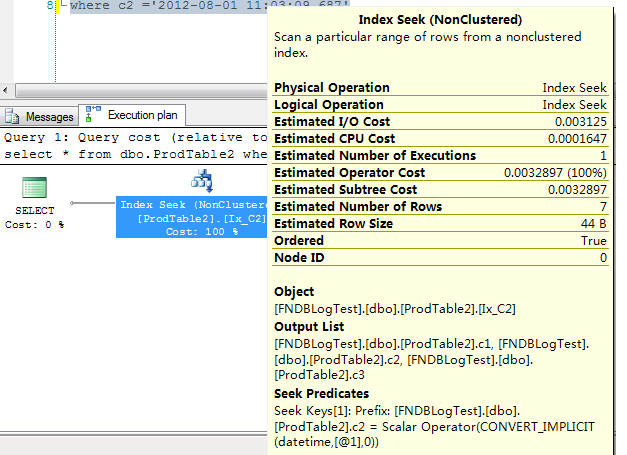




相关推荐
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。下面,我们举例来说明一下聚集索引和非聚集索引的区别: ...
As we’ll see, the clustered key is duplicated in every nonclustered index row, so keeping your clustered key small will allow you to have more index fit per page in all your indexes. Note The ...
数据库原理第三章:关系数据库标准语言SQL 数据库系统概论chp3-2全文共66页,当前为第1页。 问题 1. 模式的作用是什么?它和用户有什么关联? 2. SQL Server2008在删除模式时的默认级联选项是什么? 3.在创建数据表...
一个数据库管理系统,提供了开放的、全面的、完整的信息管理方法
描述了oracle RAC的相关内容 Oracle 11g: RAC and Grid Infrastructure Administration Accelerated Volume I - Student Guide
SQLServer中有几个可以让你检测、调整和优化SQL...当考察建立什么类型的索引时,你应当考虑数据类型和保存这些数据的column。同样,你也必须考虑数据库可能用到的查询类型以及使用的最为频繁的查询类型。 索引的类型
improvements for columnstore indexes in SQLServer 2016: updateable nonclustered columnstore indexes, columnstore indexes on in-memory tables, and many other new features for operational analytics. ...
而且随着数据量的增大,每次重新编译索引, 本身就导致SQL语句变慢. 最终解决方案: 唯一非聚集索引留着, 再添加一个 非聚集索引,保留两个索引, 终于搞定了. CREATE UNIQUE NONCLUSTERED INDEX [IX_SF_CP_Detail_MAC...
– Oracle Clusterware enables nonclustered and RAC databases to use the Oracle high-availability infrastructure. – Oracle Clusterware enables you to create a clustered pool of storage to be used by ...
相比之下,国内的相当数量的中小型医院的病人资料工作流程还采用相对保守的人工工作方式,数据信息的查询和存储的成本较高,而且效率还很低下。所以需要一种对于医院的病人资料管理系统来高效、低成本、便捷的进行...
当考察建立什么类型的索引时,你应当考虑数据类型和保存这些数据的column。同样,你也必须考虑数据库可能用到的查询类型以及使用的最为频繁的查询类型。 索引的类型 如果column保存了高度相关的数据,
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。下面,我们举例来说明一下聚集索引和非聚集索引的区别: ...
9、视图是一种常用的数据对象,它是提供(1___)和(1___)数据的另一种途径,可以简化数据库操作,当使用多个数据表来建立视图时,表的连接不能使用(2___)方式,并且不答应在该语句中包括(3___)等要害字。...
表结构如下面代码创建 代码如下: CREATE TABLE test_tb ( TestId int not null ... 代码如下: CREATE UNIQUE NONCLUSTERED INDEX un_test_tb ON test_tb(Caption) GO 索引创建好了,我们来测试下效果 代码如下: INSE
CONSTRAINT [PK_PE_Address_AddressID] PRIMARY KEY NONCLUSTERED ([AddressID]) ) ON [PRIMARY] GO EXEC sp_addextendedproperty 'MS_Description', N'地址表', 'schema', 'dbo', 'table', 'PE_Address' GO EXEC...
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)……
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。
表结构如下面代码创建 代码如下: CREATE TABLE test_tb ( TestId int not null ... 代码如下: CREATE UNIQUE NONCLUSTERED INDEX un_test_tb ON test_tb(Caption) GO 索引创建好了,我们来测试下效果 代码如下: INSE
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)……
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。下面,我们举例来说明一下聚集索引和非聚集索引的区别: ...