هچ•é“¾è،¨çڑ„ه؟«وژ’ه؛ڈه’Œو•°ç»„çڑ„ه؟«وژ’ه؛ڈهں؛وœ¬و€وƒ³ç›¸هگŒï¼ŒهگŒو ·وک¯هں؛ن؛ژهˆ’هˆ†ï¼Œن½†وک¯هڈˆوœ‰ه¾ˆه¤§çڑ„ن¸چهگŒï¼ڑهچ•é“¾è،¨ن¸چو”¯وŒپهں؛ن؛ژن¸‹و ‡çڑ„è®؟é—®م€‚و•…ن¹¦ن¸وٹٹه¾…وژ’ه؛ڈçڑ„链è،¨و‹†هˆ†ن¸؛2ن¸ھهگ链è،¨م€‚ن¸؛ن؛†ç®€هچ•èµ·è§پ,选و‹©é“¾è،¨çڑ„第ن¸€ن¸ھèٹ‚点ن½œن¸؛هں؛ه‡†ï¼Œç„¶هگژè؟›è،Œو¯”较,و¯”هں؛ه‡†ه°ڈه¾—èٹ‚点و”¾ه…¥ه·¦é¢çڑ„هگ链è،¨ï¼Œو¯”هں؛ه‡†ه¤§çڑ„و”¾ه…¥هڈ³è¾¹çڑ„هگ链è،¨م€‚هœ¨ه¯¹ه¾…وژ’ه؛ڈ链è،¨و‰«وڈڈن¸€éپچن¹‹هگژ,ه·¦è¾¹هگ链è،¨çڑ„èٹ‚点ه€¼éƒ½ه°ڈن؛ژهں؛ه‡†çڑ„ه€¼ï¼Œهڈ³è¾¹هگ链è،¨çڑ„ه€¼éƒ½ه¤§ن؛ژهں؛ه‡†çڑ„ه€¼ï¼Œç„¶هگژوٹٹهں؛ه‡†وڈ’ه…¥هˆ°é“¾è،¨ن¸ï¼Œه¹¶ن½œن¸؛è؟وژ¥ن¸¤ن¸ھهگ链è،¨çڑ„و،¥و¢پم€‚然هگژهˆ†هˆ«ه¯¹ه·¦م€پهڈ³ن¸¤ن¸ھهگ链è،¨è؟›è،Œé€’ه½’ه؟«é€ںوژ’ه؛ڈ,ن»¥وڈگé«کو€§èƒ½م€‚
ن½†وک¯ï¼Œç”±ن؛ژهچ•é“¾è،¨ن¸چ能هƒڈو•°ç»„é‚£و ·éڑڈوœ؛هکه‚¨ï¼Œه’Œو•°ç»„çڑ„ه؟«وژ’ه؛ڈ相و¯”较,è؟کوک¯وœ‰ن¸€ن؛›éœ€è¦پو³¨و„ڈçڑ„细èٹ‚ï¼ڑ
1م€پو”¯ç‚¹çڑ„选هڈ–,由ن؛ژن¸چ能éڑڈوœ؛è®؟问第Kن¸ھه…ƒç´ ,ه› و¤و¯ڈو¬،选و‹©و”¯ç‚¹و—¶هڈ¯ن»¥هڈ–ه¾…وژ’ه؛ڈ那部هˆ†é“¾è،¨çڑ„ه¤´وŒ‡é’ˆم€‚
2م€پéپچهژ†é‡ڈè،¨و–¹ه¼ڈ,由ن؛ژن¸چ能ن»ژهچ•é“¾è،¨çڑ„وœ«ه°¾هگ‘ه‰چéپچهژ†ï¼Œه› و¤ن½؟用ن¸¤ن¸ھوŒ‡é’ˆهˆ†هˆ«هگ‘ه‰چهگ‘هگژéپچهژ†çڑ„ç–ç•¥ه®و•ˆï¼Œ
ن؛‹ه®ن¸ٹ,هڈ¯ن»¥هڈ¯ن»¥é‡‡ç”¨ن¸€è¶ںéپچهژ†çڑ„و–¹ه¼ڈه°†è¾ƒه°ڈçڑ„ه…ƒç´ و”¾هˆ°هچ•é“¾è،¨çڑ„ه·¦è¾¹م€‚ه…·ن½“و–¹و³•ن¸؛ï¼ڑ
1)ه®ڑن¹‰ن¸¤ن¸ھوŒ‡é’ˆpslow,pfast,ه…¶ن¸pslowوŒ‡هگ‘هچ•é“¾è،¨çڑ„ه¤´ç»“点,pfastوŒ‡هگ‘هچ•é“¾è،¨ه¤´ç»“点çڑ„ن¸‹ن¸€ن¸ھ结点;
2)ن½؟用pfastéپچهژ†هچ•é“¾è،¨ï¼Œو¯ڈéپ‡هˆ°ن¸€ن¸ھو¯”و”¯ç‚¹ه°ڈçڑ„ه…ƒç´ ,ه°±ن»¤pslow=pslow->next,然هگژه’Œpslowè؟›è،Œو•°وچ®ن؛¤وچ¢م€‚
3م€پن؛¤وچ¢و•°وچ®و–¹ه¼ڈ,直وژ¥ن؛¤وچ¢é“¾è،¨و•°وچ®وŒ‡é’ˆوŒ‡هگ‘çڑ„部هˆ†ï¼Œن¸چه؟…ن؛¤وچ¢é“¾è،¨èٹ‚点وœ¬è؛«م€‚
هں؛ن؛ژن¸ٹè؟°و€وƒ³çڑ„هچ•é“¾è،¨ه؟«é€ںوژ’ه؛ڈه®çژ°ه¦‚ن¸‹ï¼ڑ
/**
** هچ•é“¾è،¨çڑ„ه؟«é€ںوژ’ه؛ڈ
** author :liuzhiwei
** date :2011-08-07
**/
#include<iostream>
#include<ctime>
using namespace std;
//هچ•é“¾è،¨èٹ‚点
struct SList
{
int data;
struct SList* next;
};
void bulid_slist(SList** phead, int n) //وŒ‡هگ‘وŒ‡é’ˆçڑ„وŒ‡é’ˆ
{
int i;
SList* ptr = *phead;
for(i = 0; i < n; ++i)
{
SList* temp = new SList;
temp->data = rand() % n; //ن؛§ç”ںnن¸ھnن»¥ه†…çڑ„éڑڈوœ؛و•°
temp->next = NULL;
if(ptr == NULL)
{
*phead = temp;
ptr = temp;
}
else
{
ptr->next = temp;
ptr = ptr->next;
}
}
}
void print_slist(SList* phead) //输ه‡؛链è،¨
{
SList *ptr = phead;
while(ptr)
{
printf("%d ", ptr->data);
ptr = ptr->next;
}
printf("\n");
}
void my_swap(int *a,int *b)
{
int temp;
temp=*a;
*a=*b;
*b=temp;
}
void sort_slist(SList* phead, SList* pend) //ه°†ه¤´وŒ‡é’ˆن¸؛phead,ه°¾وŒ‡é’ˆن¸؛pendçڑ„链è،¨è؟›è،Œوژ’ه؛ڈ
{
if(phead == NULL)
return ;
if(phead == pend)
return ;
SList *pslow = phead;
SList *pfast = phead->next;
SList *ptemp = phead;
while(pfast != pend)
{
if(pfast->data < phead->data) //و¯ڈو¬،都选و‹©ه¾…وژ’ه؛ڈ链è،¨çڑ„ه¤´ç»“点ن½œن¸؛هˆ’هˆ†çڑ„هں؛ه‡†
{
ptemp = pslow; //ptempه§‹ç»ˆن¸؛pslowçڑ„ه‰چ驱结点
pslow = pslow->next;
my_swap(&pslow->data , &pfast->data); //pslowوŒ‡é’ˆوŒ‡هگ‘و¯”هں؛ه‡†ه°ڈçڑ„结点组وˆگçڑ„链è،¨
}
pfast = pfast->next;
}
my_swap(&pslow->data , &phead->data); //و¤و—¶pslowوŒ‡é’ˆوŒ‡هگ‘و¯”هں؛ه‡†ه°ڈçڑ„结点组وˆگçڑ„链è،¨çڑ„وœ€هگژن¸€ن¸ھ结点,ن¹ںه°±وک¯هں؛ه‡†çڑ„ن½چ置,و‰€ن»¥è¦پن¸ژهں؛ه‡†ï¼ˆhead结点)ن؛¤وچ¢
sort_slist(phead , pslow); //ptempن¸؛ه·¦هڈ³ن¸¤éƒ¨هˆ†هˆ†ه‰²ç‚¹ï¼ˆهں؛ه‡†ï¼‰çڑ„ه‰چن¸€ن¸ھ结点
sort_slist(pslow->next , NULL); //هڈ³éƒ¨هˆ†وک¯و¯”هں؛ه‡†ه¤§çڑ„结点组وˆگçڑ„链è،¨
}
void destroy_slist(SList* phead)
{
SList* ptr = phead;
while(ptr)
{
SList* temp = ptr;
ptr = ptr->next;
delete temp;
}
}
int main(void)
{
srand(time(NULL));
printf("Before sort single list\n");
SList* phead = NULL;
bulid_slist(&phead, 100);
print_slist(phead);
printf("After sort single list\n");
sort_slist(phead, NULL);
print_slist(phead);
destroy_slist(phead);
system("pause");
return 0;
}
第ن؛Œç§چو–¹و³•ï¼ڑ
选و‹©é“¾è،¨çڑ„第ن¸€ن¸ھèٹ‚点ن½œن¸؛هں؛ه‡†ï¼Œç„¶هگژè؟›è،Œو¯”较,و¯”هں؛ه‡†ه°ڈه¾—èٹ‚点و”¾ه…¥ه·¦é¢çڑ„هگ链è،¨ï¼Œو¯”هں؛ه‡†ه¤§çڑ„و”¾ه…¥هڈ³è¾¹çڑ„هگ链è،¨م€‚هœ¨ه¯¹ه¾…وژ’ه؛ڈ链è،¨و‰«وڈڈن¸€éپچن¹‹هگژ,ه·¦é¢هگ链è،¨çڑ„èٹ‚点ه€¼éƒ½ه°ڈن؛ژهں؛ه‡†çڑ„ه€¼ï¼Œهڈ³è¾¹هگ链è،¨çڑ„ه€¼éƒ½ه¤§ن؛ژهں؛ه‡†çڑ„ه€¼ï¼Œç„¶هگژوٹٹهں؛ه‡†وڈ’ه…¥هˆ°é“¾è،¨ن¸ï¼Œه¹¶ن½œن¸؛è؟وژ¥ن¸¤ن¸ھهگ链è،¨çڑ„و،¥و¢پم€‚然هگژو ¹وچ®ه·¦م€پهڈ³هگ链è،¨ن¸èٹ‚点و•°ï¼Œé€‰و‹©è¾ƒه°ڈçڑ„è؟›è،Œé€’ه½’ه؟«é€ںوژ’ه؛ڈ,而ه¯¹و•°ç›®è¾ƒه¤ڑçڑ„هˆ™è؟›è،Œè؟ن»£وژ’ه؛ڈم€‚
وژ’ه؛ڈه‡½و•°ن¸ن½؟用çڑ„هڈکé‡ڈه¦‚ن¸‹ï¼ڑ
struct node *right; //هڈ³è¾¹هگ链è،¨çڑ„第ن¸€ن¸ھèٹ‚点
struct node **left_walk, **right_walk; //ن½œن¸؛وŒ‡é’ˆï¼Œوٹٹه…¶وŒ‡هگ‘çڑ„èٹ‚点هٹ ه…¥هˆ°ç›¸ه؛”çڑ„هگ链è،¨ن¸
struct node *pivot, *old; //pivotن¸؛هں؛ه‡†, oldن¸؛ه¾ھçژ¯و•´ن¸ھه¾…وژ’ه؛ڈ链è،¨çڑ„وŒ‡é’ˆ
و ¸ه؟ƒن»£ç په¦‚ن¸‹ï¼ڑ
for (old = (*head)->next; old != end; old = old->next) {
if (old->data < pivot->data) { //ه°ڈن؛ژهں؛ه‡†,هٹ ه…¥هˆ°ه·¦é¢çڑ„هگ链è،¨,继ç»و¯”较
++left_count;
*left_walk = old; //وٹٹ该èٹ‚点هٹ ه…¥هˆ°ه·¦è¾¹çڑ„链è،¨ن¸ï¼Œ
left_walk = &(old->next);
} else { //ه¤§ن؛ژهں؛ه‡†,هٹ ه…¥هˆ°هڈ³è¾¹çڑ„هگ链è،¨ï¼Œç»§ç»و¯”较
++right_count;
*right_walk = old;
right_walk = &(old->next);
}
}
headن¸؛struct node **ç±»ه‹ï¼ŒوŒ‡هگ‘链è،¨ه¤´éƒ¨ï¼ŒendوŒ‡هگ‘链è،¨ه°¾éƒ¨ï¼Œهڈ¯ن¸؛NULL,è؟™و®µç¨‹ه؛ڈçڑ„é‡چ点هœ¨ن؛ژوŒ‡é’ˆçڑ„وŒ‡é’ˆçڑ„用و³•ï¼Œ*left_walkن¸؛ن¸€ن¸ھوŒ‡هگ‘nodeèٹ‚点çڑ„وŒ‡é’ˆï¼Œè¯´çڑ„وکژ白点*left_walkçڑ„ه€¼ه°±وک¯nodeèٹ‚点çڑ„ه†…هکهœ°ه€ï¼Œه…¶ه®è؟کوœ‰ن¸€ن¸ھهœ°و–¹ن¹ںوœ‰nodeçڑ„هœ°ه€ï¼Œé‚£ه°±وک¯وŒ‡هگ‘nodeçڑ„èٹ‚点çڑ„nextهںں,و•…وˆ‘ن»¬هڈ¯ن»¥ç®€هچ•çڑ„认ن¸؛*left_walk = oldه°±وک¯وٹٹوŒ‡هگ‘nodeèٹ‚点çڑ„èٹ‚点çڑ„nextهںںو”¹ن¸؛èٹ‚点oldçڑ„هœ°ه€ï¼Œè؟™و ·هڈ¯èƒ½é€ وˆگن¸¤ç§چوƒ…ه†µï¼ڑن¸€ç§چه°±وک¯*left_walkوœ¬و¥ه°±وŒ‡هگ‘oldèٹ‚点,è؟™و ·ه°±و²،وœ‰و”¹هڈکن»»ن½•و”¹هڈک,هڈ¦ن¸€ç§چهˆ™وک¯و”¹هڈکن؛†*right_walkوŒ‡هگ‘èٹ‚点çڑ„ه‰چن¸€ن¸ھèٹ‚点çڑ„nextهںں,ن½؟ه…¶وŒ‡هگ‘هگژ部çڑ„èٹ‚点,ن¸é—´è·³è؟‡ن؛†è‹¥ه¹²ن¸ھèٹ‚点,ن¸چè؟‡هœ¨è؟™é‡Œè؟™و ·هپڑه¹¶ن¸چن¼ڑé€ وˆگن»»ن½•é—®é¢ک,ه› ن¸؛链è،¨ن¸çڑ„èٹ‚点è¦پن¹ˆهٹ ه…¥هˆ°ه·¦é¢çڑ„هگ链è،¨ن¸ï¼Œè¦پن¹ˆهٹ ه…¥هˆ°هڈ³é¢çڑ„هگ链è،¨ن¸ï¼Œن¸چن¼ڑه‡؛çژ°èٹ‚点ن¸¢ه¤±çڑ„وƒ…ه†µم€‚
ن¸‹é¢ç”¨ه›¾ç¤؛说وکژن¸‹ن¸ٹé¢çڑ„é—®é¢کï¼ڑ
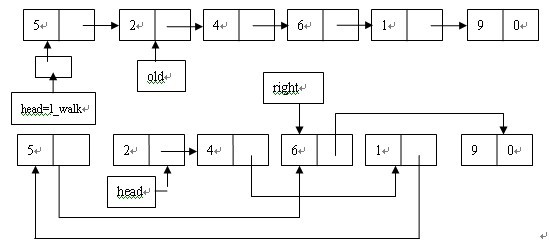
è؟™é‡Œهپ‡è®¾é“¾è،¨çڑ„ه€¼ن¸€و¬،وک¯5م€پ2م€پ4م€پ6م€پ1م€‚و ¹وچ®ç¨‹ه؛ڈ首ه…ˆhead = left_walkوŒ‡هگ‘ه€¼ن¸؛5çڑ„èٹ‚点,oldوŒ‡هگ‘ه€¼ن¸؛2çڑ„èٹ‚点,2ه°ڈن؛ژ5,و‰€ن»¥هٹ ه…¥2هˆ°ه·¦é¢çڑ„هگ链è،¨ن¸ï¼Œ*left_walk=old,وˆ‘ن»¬çں¥éپ“,*left_walkوŒ‡هگ‘çڑ„وک¯ç¬¬ن¸€ن¸ھèٹ‚点,è؟™و ·هپڑو”¹هڈکن؛†headوŒ‡é’ˆه€¼ï¼Œن½؟ه…¶وŒ‡هگ‘第ن؛Œن¸ھèٹ‚点,然هگژleft_walkهگژ移,oldهگژ移,4هگŒو ·ه°ڈن؛ژ5,و•…继ç»ن¸ٹè؟°و“چن½œï¼Œن½†وک¯è؟™وک¯*left_walkه’ŒoldوŒ‡هگ‘çڑ„وک¯هگŒن¸€ن¸ھèٹ‚点,و²،وœ‰ه¼•èµ·ن»»ن½•هڈکهŒ–,left_walkه’Œoldهگژ移,6ه¤§ن؛ژ5,è؟™و—¶ن¸چهگŒه°±ه‡؛çژ°ن؛†ï¼Œè¦پوٹٹه…¶هٹ ه…¥هˆ°هڈ³è¾¹çڑ„هگ链è،¨ن¸ï¼Œو•…وک¯*right_walk
= old,ه…¶ه®right_walkهˆè¯•هŒ–ن¸؛&right,è؟™هڈ¥è¯ç›¸ه½“ن؛ژright = old,هچ³ن»¤oldه½“ه‰چوŒ‡هگ‘çڑ„èٹ‚点ن½œن¸؛هڈ³è¾¹هگ链è،¨çڑ„第ن¸€ن¸ھèٹ‚点,ن»¥هگژه¤§ن؛ژهں؛ه‡†çڑ„èٹ‚点都è¦پهٹ ه…¥هˆ°è؟™ن¸ھèٹ‚点ن¸ï¼Œن¸”و€»وک¯هٹ ه…¥هˆ°ه°¾éƒ¨م€‚و¤و—¶right_walk,ه’Œoldهگژ移,1ه°ڈن؛ژ5ه؛”该هٹ ه…¥هˆ°ه·¦è¾¹çڑ„هگ链è،¨ن¸ï¼Œ*left_walk = old,و¤و—¶*left_walkوŒ‡هگ‘6,و•…و¤è¯هڈ¥çڑ„ن½œç”¨وک¯و›´و”¹èٹ‚点4çڑ„nextه€¼ï¼Œوٹٹه…¶و”¹ن¸؛1çڑ„هœ°ه€ï¼Œè؟™و ·6ه°±ن»ژهژںو¥çڑ„链è،¨ن¸è„±é’©ن؛†ï¼Œç»§ç»left_walkه’Œoldهگژ移هˆ°9èٹ‚点,ه؛”هٹ ه…¥هˆ°هڈ³è¾¹çڑ„هگ链è،¨ن¸ï¼Œو¤و—¶*right_walkوŒ‡هگ‘1,و•…وٹٹ9èٹ‚点هٹ ه…¥هˆ°6èٹ‚点çڑ„هگژé¢م€‚
è؟™ه°±وک¯هں؛وœ¬çڑ„وژ’ه؛ڈè؟‡ç¨‹ï¼Œç„¶è€Œوœ‰ن¸€ن¸ھé—®é¢ک需è¦پوگوکژ白,و¯”ه¦‚وœ‰èٹ‚点ن¾و¬،ن¸؛struct node *a, *b, *c,node **p , p = &b,ه¦‚وœو¤و—¶ن»¤*p = c,هچ³ه®é™…و•ˆوœوک¯a->next = cï¼›وˆ‘ن»¬çں¥éپ“è؟™ç›¸ه½“ن؛ژ该açڑ„nextهںںçڑ„ه€¼م€‚而pن»…ن»…وک¯ن¸€ن¸ھوŒ‡é’ˆçڑ„وŒ‡é’ˆï¼Œه®ƒوک¯وŒ‡هگ‘bو‰€وŒ‡هگ‘çڑ„èٹ‚点çڑ„هœ°ه€çڑ„وŒ‡é’ˆï¼Œé‚£ن¹ˆه½“وˆ‘ن»¬و›´و”¹*pçڑ„ه€¼çڑ„و—¶ه€™و€ژن¹ˆن¼ڑو”¹هˆ°ن؛†açڑ„nextه‘¢(è؟™ن¸ھهڈ¯ن»¥ه†™ç¨‹ه؛ڈéھŒè¯پن¸‹ï¼Œç،®ه®ه¦‚و¤)ï¼ںه…¶ه®ه¹¶éه¦‚و¤ï¼Œوˆ‘ن»¬ن»”细çڑ„看看程ه؛ڈ,left_walkهˆه§‹هŒ–ن¸؛head,那ن¹ˆç¬¬ن¸€و¬،و‰§è،Œ*left_walkوک¯وٹٹheadوŒ‡هگ‘ن؛†ه·¦è¾¹é“¾è،¨çڑ„èµ·ه§‹èٹ‚点,然هگژleft_walk被赋ه€¼ن¸؛&(old->next),è؟™هڈ¥è¯ه°±وœ‰و„ڈو€ن؛†ï¼Œوˆ‘ن»¬çœ‹ن¸€çœ‹ن¸‹é¢هœ¨و‰§è،Œ*left_walk=oldو—¶çڑ„وƒ…ه†µï¼Œهڈ¯ن»¥ç®€هچ•çڑ„و¥ن¸ھç‰ن»·و›؟وچ¢ï¼Œ*left_walk
= oldن¹ںه°±ç›¸ه½“ن؛ژ*&(old->next) = old,هچ³old->nex = old,ن¸چè؟‡è؟™é‡Œçڑ„oldهڈ¯ن¸چن¸€ه®ڑوک¯old->nextو‰€وŒ‡هگ‘çڑ„èٹ‚点,ه؛”ن¸؛left_walkه’Œright_walk都وŒ‡هگ‘ه®ƒن»¬çڑ„oldèٹ‚点,ن½†وک¯هچ´وک¯ن¸چهگŒçڑ„م€‚
ç®—و³•هˆ°è؟™é‡Œه¹¶و²،وœ‰ه®Œï¼Œè؟™هڈھوک¯و‰§è،Œن؛†ن¸€و¬،هˆ’هˆ†ï¼Œوٹٹهں؛ه‡†و”¾ه…¥ن؛†و£ç،®çڑ„ن½چ置,è؟کè¦پ继ç»ï¼Œن¸چè؟‡ن¸‹é¢çڑ„ه°±و¯”较简هچ•ن؛†ï¼Œه°±وک¯é€’ه½’وژ’ه؛ڈن¸ھو•°و¯”较ه°ڈçڑ„هگ链è،¨ï¼Œè؟ن»£ه¤„çگ†èٹ‚点و•°ç›®و¯”较ه¤§çڑ„هگ链è،¨م€‚
ه®Œو•´çڑ„ن»£ç په¦‚ن¸‹ï¼ڑ
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//链è،¨èٹ‚点
struct node
{
int data;
struct node *next;
};
//链è،¨ه؟«وژ’ه؛ڈه‡½و•°
void QListSort(struct node **head,struct node *h);
//و‰“هچ°é“¾è،¨
void print_list(struct node *head)
{
struct node *p;
for (p = head; p != NULL; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}
int main(void)
{
struct node *head = NULL;
struct node *p;
int i;
/**
* هˆه§‹هŒ–链è،¨
*/
srand((unsigned)time(NULL));
for (i = 1; i < 11; ++i)
{
p = (struct node*)malloc(sizeof(struct node));
p->data = rand() % 100 + 1;
if(head == NULL)
{
head = p;
head->next = NULL;
}
else
{
p->next = head->next;
head->next = p;
}
}
print_list(head);
printf("---------------------------------\n");
QListSort(&head,NULL);
print_list(head);
system("pause");
return 0;
}
void QListSort(struct node **head, struct node *end)
{
struct node *right;
struct node **left_walk, **right_walk;
struct node *pivot, *old;
int count, left_count, right_count;
if (*head == end)
return;
do {
pivot = *head;
left_walk = head;
right_walk = &right;
left_count = right_count = 0;
//هڈ–第ن¸€ن¸ھèٹ‚点ن½œن¸؛و¯”较çڑ„هں؛ه‡†ï¼Œه°ڈن؛ژهں؛ه‡†çڑ„هœ¨ه·¦é¢çڑ„هگ链è،¨ن¸ï¼Œ
//ه¤§ن؛ژهں؛ه‡†çڑ„هœ¨هڈ³è¾¹çڑ„هگ链è،¨ن¸
for (old = (*head)->next; old != end; old = old->next)
{
if (old->data < pivot->data)
{ //ه°ڈن؛ژهں؛ه‡†,هٹ ه…¥هˆ°ه·¦é¢çڑ„هگ链è،¨,继ç»و¯”较
++left_count;
*left_walk = old; //وٹٹ该èٹ‚点هٹ ه…¥هˆ°ه·¦è¾¹çڑ„链è،¨ن¸ï¼Œ
left_walk = &(old->next);
}
else
{ //ه¤§ن؛ژهں؛ه‡†,هٹ ه…¥هˆ°هڈ³è¾¹çڑ„هگ链è،¨ï¼Œç»§ç»و¯”较
++right_count;
*right_walk = old;
right_walk = &(old->next);
}
}
//هگˆه¹¶é“¾è،¨
*right_walk = end; //结وںهڈ³é“¾è،¨
*left_walk = pivot; //وٹٹهں؛ه‡†ç½®ن؛ژو£ç،®çڑ„ن½چç½®ن¸ٹ
pivot->next = right; //وٹٹ链è،¨هگˆه¹¶
//ه¯¹è¾ƒه°ڈçڑ„هگ链è،¨è؟›è،Œه؟«وژ’ه؛ڈ,较ه¤§çڑ„هگ链è،¨è؟›è،Œè؟ن»£وژ’ه؛ڈم€‚
if(left_walk > right_walk)
{
QListSort(&(pivot->next), end);
end = pivot;
count = left_count;
}
else
{
QListSort(head, pivot);
head = &(pivot->next);
count = right_count;
}
}
while (count > 1);
}
هˆ†ن؛«هˆ°ï¼ڑ




相ه…³وژ¨èچگ
ه¤§ه¦وˆ–è€…è€ƒç ”و—¶و•°وچ®ç»“و„هچ•é“¾è،¨ه؟«é€ںوژ’ه؛ڈé—®é¢ک,و•°وچ®ç»“و„çڑ„هں؛ç،€ن»£ç پم€‚
该و–‡ن»¶هŒ…هگ«ن؛†Cè¯è¨€ن¸‹çڑ„هچ•é“¾è،¨çڑ„ç®—و³•ه®çژ°م€‚
هچ•é“¾è،¨ه؟«é€ںوژ’ه؛ڈ VC++ WIN32 Console Application
然هگژهˆ†هˆ«ه¯¹ه·¦م€پهڈ³ن¸¤ن¸ھهگ链è،¨è؟›è،Œé€’ه½’ه؟«é€ںوژ’ه؛ڈ,ن»¥وڈگé«کو€§èƒ½م€‚ن½†وک¯ï¼Œç”±ن؛ژهچ•é“¾è،¨ن¸چ能هƒڈو•°ç»„é‚£و ·éڑڈوœ؛هکه‚¨ï¼Œه’Œو•°ç»„çڑ„ه؟«وژ’ه؛ڈ相و¯”较,è؟کوک¯وœ‰ن¸€ن؛›éœ€è¦پو³¨و„ڈçڑ„细èٹ‚ï¼ڑ1م€پو”¯ç‚¹çڑ„选هڈ–,由ن؛ژن¸چ能éڑڈوœ؛è®؟问第Kن¸ھه…ƒç´ ,ه› و¤و¯ڈ
简هچ•وکژن؛†çڑ„ه®çژ°ه؟«é€ںوژ’ه؛ڈ,éه¸¸و¸…و¥ڑçڑ„و€è·¯ int main() { quicksort(); }
هچ•هگ‘链è،¨ه®çژ°ه€’置,ه†’و³،وژ’ه؛ڈ,وڈ’ه…¥وژ’ه؛ڈ,ه؟«é€ںوژ’ه؛ڈ,هœ¨linuxن¸‹çڑ„gccه®çژ°
ه…³ن؛ژهچ•é“¾è،¨çڑ„ه؟«é€ںوژ’ه؛ڈ ه †وژ’ه؛ڈه’Œه†’و³،وژ’ه؛ڈ,هں؛ن؛ژوŒ‡é’ˆçڑ„ن؛¤وچ¢ï¼Œه¯¹çگ†è§£وŒ‡é’ˆهپ¶ه¸®هٹ©
[ç®—و³•]ه؟«é€ںوژ’ه؛ڈ,ه½’ه¹¶وژ’ه؛ڈ,ه †وژ’ه؛ڈçڑ„و•°ç»„ه’Œهچ•é“¾è،¨ه®çژ° و•°ç»„ه’Œé“¾è،¨.pdf
[ç®—و³•]ه؟«é€ںوژ’ه؛ڈ,ه½’ه¹¶وژ’ه؛ڈ,ه †وژ’ه؛ڈçڑ„و•°ç»„ه’Œهچ•é“¾è،¨ه®çژ° (1) و•°ç»„ه’Œé“¾è،¨.pdf
هچ•é“¾è،¨ه؟«é€ںوژ’ه؛ڈ](链è،¨/148.\ هچ•é“¾è،¨ه؟«é€ںوژ’ه؛ڈ.md) [215. و•°ç»„ن¸çڑ„第Kن¸ھوœ€ه¤§ه…ƒç´ ](و•°ç»„/0215.\ و•°ç»„ن¸çڑ„第Kن¸ھوœ€ه¤§ه…ƒç´ .md) [229. و±‚ن¼—و•° II](و•°ç»„/0229.\ و±‚ن¼—و•°\ II.md) [230. ن؛Œهڈ‰وگœç´¢و ‘ن¸ç¬¬Kه°ڈçڑ„ه…ƒç´ ](و ‘/0230.\ ...
هچ•é“¾è،¨ه؟«é€ںوژ’ه؛ڈ هچ•é“¾è،¨ه½’ه¹¶وژ’ه؛ڈ هڈŒهگ‘链è،¨ ه¾ھçژ¯é“¾è،¨ 链è،¨ن¸وں¥و‰¾ه…ƒç´ م€پو·»هٹ ه…ƒç´ çڑ„و—¶é—´ه¤چو‚ه؛¦هˆ†وگ و•°ç»„ه’Œé“¾è،¨çڑ„ن¸چهگŒهŒ؛هˆ«هœ¨ه“ھ里 ن½؟用链è،¨ه®çژ°LRU 3. و ˆ و ˆçڑ„هں؛وœ¬و¦‚ه؟µ 链ه¼ڈو ˆ و ˆوک¯هگ¦ن¸؛ç©؛ و‹¬هڈ·هŒ¹é…چ ه¦‚ن½•ه®çژ°وµڈ览ه™¨çڑ„ه‰چè؟›ه’Œ...
06و•°وچ®ç»“و„-هچ•é“¾è،¨çڑ„هکه‚¨ç»“و„,07و•°وچ®ç»“و„-هچ•é“¾è،¨çڑ„هˆ›ه»؛ن¸ژéپچهژ†ï¼Œ08و•°وچ®ç»“و„-هچ•é“¾è،¨çڑ„وں¥و‰¾ه’Œوڈ’ه…¥ï¼Œ09و•°وچ®ç»“و„-هچ•é“¾è،¨çڑ„هˆ 除ه’Œه€’置,10و•°وچ®ç»“و„-هچ•é“¾è،¨çڑ„وœ‰ه؛ڈوڈ’ه…¥ه’Œوژ’ه؛ڈ,用Cè¯è¨€هœ¨Linuxن¸‹ه†™çڑ„,هڈ¯ن»¥ه؟«é€ں移و¤چهˆ°هگ„ه¹³هڈ°
C#,هڈŒهگ‘链è،¨ï¼ˆDoubly Linked List)ه؟«é€ںوژ’ه؛ڈ(Quick Sort)算و³•ن¸ژو؛گن»£ç پم€‚هڈŒهگ‘链è،¨ن¹ںهڈ«هڈŒé“¾è،¨ï¼Œوک¯é“¾è،¨çڑ„ن¸€ç§چ,ه®ƒçڑ„و¯ڈن¸ھو•°وچ®ç»“点ن¸éƒ½وœ‰ن¸¤ن¸ھوŒ‡é’ˆï¼Œهˆ†هˆ«وŒ‡هگ‘ç›´وژ¥هگژ继ه’Œç›´وژ¥ه‰چ驱م€‚و‰€ن»¥ï¼Œن»ژهڈŒهگ‘链è،¨ن¸çڑ„ن»»و„ڈن¸€ن¸ھ结点ه¼€ه§‹...
ه؟«é€’وژ’ه؛ڈçڑ„第ن¸€ç§چو€وƒ³ï¼ˆن»¥ن¸‹éƒ½ن»¥هچ‡ه؛ڈن¸؛ن¾‹ï¼‰ï¼ڑهپ‡è®¾ن¸€ن¸ھو•°ç»„a, 设置ن¸€ن¸ھهں؛ه‡†و•°povit,然هگژن¸¤ن¸ھوŒ‡é’ˆهˆ†هˆ«وŒ‡هگ‘و•°ç»„çڑ„ه¼€ه§‹ه’Œç»“وں,هپ‡è®¾ن¸؛i, jن»ژjه¼€ه§‹ه¾€ه‰چ走,走هˆ°ه°ڈن؛ژpovitه€¼ه¾—و—¶ه€™هپœن¸‹و¥ï¼Œç„¶هگژiن»ژه‰چه¾€هگژ走,走هˆ°ه¤§ن؛ژpovit...
用VCç¼–ه†™çڑ„ç؛؟و€§è،¨ه°±هœ°é€†ç½®ï¼Œèµ«ه¤«و›¼و ‘,ه؟«é€ںوژ’ه؛ڈçڑ„ن»£ç پçڑ„ه®éھŒوٹ¥ه‘ٹ
/* 1.هˆه§‹هŒ–ç؛؟و€§è،¨ï¼Œهچ³ç½®هچ•é“¾è،¨çڑ„è،¨ه¤´وŒ‡é’ˆن¸؛ç©؛ *//* 2.هˆ›ه»؛ç؛؟و€§è،¨ï¼Œو¤ه‡½و•°è¾“ه…¥è´ںو•°ç»ˆو¢è¯»هڈ–و•°وچ®*//* 3.و‰“هچ°é“¾è،¨ï¼Œé“¾è،¨çڑ„éپچهژ†*//* 4.و¸…除ç؛؟و€§è،¨Lن¸çڑ„و‰€وœ‰ه…ƒç´ ,هچ³é‡ٹو”¾هچ•é“¾è،¨Lن¸و‰€وœ‰çڑ„结点,ن½؟...ه°†ç؛؟و€§è،¨è؟›è،Œه؟«é€ںوژ’ه؛ڈ */
1م€پ链è،¨وژ’ه؛ڈ [é—®é¢کوڈڈè؟°]م€€ه»؛ç«‹ن¸€ن¸ھ...设è®،è¦پو±‚ï¼ڑهˆ©ç”¨éڑڈوœ؛ه‡½و•°ن؛§ç”ں10ن¸ھو ·وœ¬ï¼Œو¯ڈن¸ھو ·وœ¬وœ‰20000éڑڈوœ؛و•´و•°ï¼Œهˆ©ç”¨ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈ,ه†’و³،وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€په †وژ’ه؛ڈ,ه½’ه¹¶وژ’ه؛ڈ,هں؛و•°وژ’ه؛ڈه…«ç§چوژ’ه؛ڈو–¹و³•è؟›è،Œوژ’ه؛ڈ
è؟™ن¸ھه¤´و–‡ن»¶ه®çژ°ن؛†é“¾è،¨وœ‰ه…³çڑ„هں؛وœ¬و“چن½œï¼ŒهŒ…و‹¬ï¼ڑهڈ‘çژ°é“¾è،¨وک¯هگ¦وœ‰çژ¯م€پو±‚çژ¯ه…¥هڈ£هڈٹçژ¯é•؟ه؛¦م€پو±‚ن¸¤ن¸ھ链è،¨وک¯هگ¦ç›¸ن؛¤م€پهڈچ转链è،¨م€پè؟کوœ‰هگ„ç§چوژ’ه؛ڈو“چن½œï¼Œهں؛ن؛ژ链è،¨çڑ„وڈ’ه…¥وژ’ه؛ڈ,ه†’و³،وژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€پهگˆه¹¶وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈ