verilog实现乘法器
以下介绍两种实现乘法器的方法:串行乘法器和流水线乘法器。
1)串行乘法器
两个N位二进制数x、y的乘积用简单的方法计算就是利用移位操作来实现。
其框图如下:
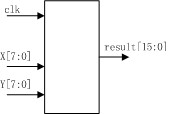
其状态图如下:
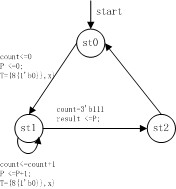
其实现的代码如下:
modulemulti_CX(clk,
x, y, result);
|
09
|
parameters0
= 0, s1 = 1, s2 = 2;
|
15
|
always@(posedgeclk)begin
|
缺点:乘法功能是正确的,但计算一次乘法需要8个周期,因此可以看出串行乘法器速度比较慢、时延大
。
优点:该乘法器所占用的资源是所有类型乘法器中最少的,在低速的信号处理中有广泛的使用。
2)流水线乘法器
一般的快速乘法器通常采用逐位并行的迭代阵列结构,将每个操作数的N位都并行地提交给乘法器。但是一般对于FPGA来讲,进位的速度快于加法的速度,这种阵列结构并不是最优的。所以可以采用多级流水线的形式,将相邻的两个部分乘积结果再加到最终的输出乘积上,即排成一个二叉树形式的结构,这样对于N位乘法器需要log2(N)级来实现,
一个8位乘法器,其原理图如下图所示:
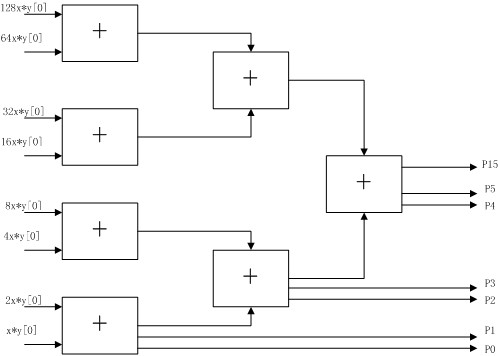
其实现的代码如下:
module multi_4bits_pipelining(mul_a, mul_b, clk, rst_n, mul_out);
input [3:0] mul_a, mul_b;
input clk;
input rst_n;
output [15:0] mul_out;
reg [15:0] mul_out;
reg [15:0] stored0;
reg [15:0] stored1;
reg [15:0] stored2;
reg [15:0] stored3;
reg [15:0] stored4;
reg [15:0] stored5;
reg [15:0] stored6;
reg [15:0] stored7;
reg [15:0] mul_out01;
reg [15:0] mul_out23;
reg [15:0] add01;
reg [15:0] add23;
reg [15:0] add45;
reg [15:0] add67;
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
mul_out <= 0;
stored0 <= 0;
stored1 <= 0;
stored2 <= 0;
stored3 <= 0;
stored4 <= 0;
stored5 <= 0;
stored6 <= 0;
stored7 <= 0;
add01 <= 0;
add23 <= 0;
add45 <= 0;
add67 <= 0;
end
else begin
stored0 <= mul_b[0]? {8'b0, mul_a} : 16'b0;
stored1 <= mul_b[1]? {7'b0, mul_a, 1'b0} : 16'b0;
stored2 <= mul_b[2]? {6'b0, mul_a, 2'b0} : 16'b0;
stored3 <= mul_b[3]? {5'b0, mul_a, 3'b0} : 16'b0;
stored4 <= mul_b[0]? {4'b0, mul_a, 4'b0} : 16'b0;
stored5 <= mul_b[1]? {3'b0, mul_a, 5'b0} : 16'b0;
stored6 <= mul_b[2]? {2'b0, mul_a, 6'b0} : 16'b0;
stored7 <= mul_b[3]? {1'b0, mul_a, 7'b0} : 16'b0;
add01 <= stored1 + stored0;
add23 <= stored3 + stored2;
add45 <= stored5 + stored4;
add67 <= stored7 + stored6;
mul_out01 <= add01 + add23;
mul_out23 <= add45 + add67;
mul_out <= mul_out01 + mul_out23;
end
end
endmodule
流水线乘法器比串行乘法器的速度快很多很多,在非高速的信号处理中有广泛的应用。至于高速信号的乘法一般需要利用FPGA芯片中内嵌的硬核DSP单元来实现。
注:本文大部分内容转自http://www.cnblogs.com/shengansong/archive/2011/05/23/2054401.html。
分享到:




相关推荐
用Verilog实现阵列乘法器,采用的是流水线的做法
包含有符号乘法器以及无符号乘法器的Verilog源码,同时带有tb文件用于仿真测试,在Vivado和Modelsim上验证通过
包含MULT、MULTU的v文件以及对应的testbank文件,代码带注释。
fpga verilog 16位有符号数乘法器,
Verilog 4位乘法器设计实现4位二进制数的乘法运算
基于FPGA Verilog串行乘法器DSP设计,代码通过仿真和下板调试,串行的DSP消耗的时间相对较长,但是占用资源较少
利用verilog实现的四位节省进位乘法器,最大延时为3.372ns,资源为16个LUT
利用verilog语言实现了逐次进位乘法器,延时达到3.549ns,资源使用了24个LUT
改进的verilog乘法器,改进了此项乘法,更利于在硬件中的使用
基于verilog的乘法器实现,先实现了加法器,在实现乘法器。 环境为quatusII
包括流水线,用一个移位寄存器和一个加法器就能完成乘以 3 的操作。但是乘以 15 时就需要 3 个移位寄存器和 3 个加法器(当然乘以 15 可以用移位相减的方式)。 有时候数字电路在一个周期内并不能够完成多个变量同时...
Verilog开发的乘法器代码,可以实现两个8位无符号数的乘法运算。仿真通过
verilog 带符号乘法器代码,先求绝对值,最后保存符号位。
用Verilog描写的乘法器,经验证,含源代码
使用verilog实现了设计了一个符合IEEE标准的32位单精度浮点数乘法器,并使用Modelsim进行仿真。
256位时序乘法器,的Verilog RTL代码,个人学习时用的,可供参考
4位并行乘法器的电路设计与仿真 1. 实现4位并行乘法器的电路设计; 2. 带异步清零端; 3. 输出为8位; 4. 单个门延迟设为5 ns。
复数乘法器本身十分很简单,这里复数乘法器的乘积项的计算调用了wallace树乘法器,故本乘法器的verilog HDL代码中包括了wallace树乘法器模块。仔细内容请浏览我的博客。
vivado 调用乘法器IP核实现乘法运算
8位Booth乘法器设计,8位乘8位的基2的booth乘法器的verilog实现。满足1)利用硬件描述语言描述8位数乘法器运算;2)输入为复位信号、乘法执行按键;3)时钟信号为开发板上时钟信号。